介绍
10 分钟内你需要了解的有关 Kafka 的一切
(点击图片将从 YouTube 加载视频)

什么是事件流?
事件流相当于人体中枢神经系统的数字化。它是“永远在线”世界的技术基础,在这个世界中,企业越来越多地由软件定义和自动化,软件的用户更多地是软件。
从技术上讲,事件流是以事件流的形式从数据库、传感器、移动设备、云服务和软件应用程序等事件源实时捕获数据的实践;持久存储这些事件流以供以后检索;实时和回顾性地操作、处理事件流并对其做出反应;并根据需要将事件流路由到不同的目标技术。因此,事件流可确保数据的连续流动和解释,以便正确的信息在正确的时间出现在正确的地点。
我可以使用事件流做什么?
事件流适用于 众多行业和组织的各种用例。它的许多例子包括:
- 实时处理支付和金融交易,例如在证券交易所、银行和保险中。
- 实时跟踪和监控汽车、卡车、车队和货运,例如物流和汽车行业。
- 持续捕获和分析来自物联网设备或其他设备(例如工厂和风电场)的传感器数据。
- 收集客户互动和订单并立即做出反应,例如零售、酒店和旅游业以及移动应用程序。
- 监测医院护理中的患者并预测病情变化,以确保在紧急情况下及时得到治疗。
- 连接、存储并提供公司不同部门生成的数据。
- 作为数据平台、事件驱动架构和微服务的基础。
Apache Kafka® 是一个事件流平台。这意味着什么?
Kafka 结合了三个关键功能,因此您可以使用 一个经过实战检验的解决方案来实现端到端事件流的 用例:
- 发布(写入)和订阅(读取)事件流,包括从其他系统持续导入/导出数据。
- 根据需要持久可靠地存储事件 流。
- 在事件发生时或回顾性地 处理 事件流。
所有这些功能都是以分布式、高度可扩展、弹性、容错和安全的方式提供的。Kafka 可以部署在裸机硬件、虚拟机和容器上,也可以部署在本地和云端。您可以选择自行管理 Kafka 环境,也可以选择使用各种供应商提供的完全托管服务。
简而言之,Kafka 是如何工作的?
Kafka是一个分布式系统,由通过高性能TCP网络协议进行通信的服务器和客户端组成。它可以部署在本地和云环境中的裸机硬件、虚拟机和容器上。
服务器:Kafka 作为一台或多台服务器的集群运行,可以跨越多个数据中心或云区域。其中一些服务器形成存储层,称为代理。其他服务器运行 Kafka Connect以持续导入和导出数据作为事件流,以将 Kafka 与您现有的系统(例如关系数据库以及其他 Kafka 集群)集成。为了让您实现关键任务用例,Kafka 集群具有高度可扩展性和容错性:如果其中任何服务器发生故障,其他服务器将接管其工作,以确保连续运行而不会丢失任何数据。
客户端:它们允许您编写分布式应用程序和微服务,即使在网络问题或机器故障的情况下,也可以以容错的方式并行、大规模地读取、写入和处理事件流。Kafka 附带了一些此类客户端,并由 Kafka 社区提供的数十个客户端进行了扩充:客户端可用于 Java 和 Scala,包括更高级别的 Kafka Streams库,适用于 Go、Python、C/C++ 和许多其他编程语言以及 REST API。
主要概念和术语
事件记录了世界上或您的企业中“发生了一些事情”的事实。在文档中也称为记录或消息。当您向 Kafka 读取或写入数据时,您以事件的形式执行此操作。从概念上讲,事件具有键、值、时间戳和可选的元数据标头。这是一个示例事件:
- 事件键:“爱丽丝”
- 事件值:“向 Bob 支付了 200 美元”
- 事件时间戳:“2020 年 6 月 25 日下午 2:06”
生产者是将事件发布(写入)到 Kafka 的客户端应用程序,而消费者是订阅(读取和处理)这些事件的客户端应用程序。在 Kafka 中,生产者和消费者彼此完全解耦且互不可知,这是实现 Kafka 闻名的高可扩展性的关键设计元素。例如,生产者永远不需要等待消费者。Kafka 提供了各种保证,例如一次性处理事件的能力。
事件被组织并持久存储在主题中。非常简单,主题类似于文件系统中的文件夹,事件是该文件夹中的文件。示例主题名称可以是“付款”。Kafka 中的主题始终是多生产者和多订阅者:一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。主题中的事件可以根据需要随时读取——与传统消息传递系统不同,事件在使用后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应保留事件的时间,之后旧事件将被丢弃。Kafka 的性能在数据大小方面实际上是恒定的,因此长时间存储数据是完全可以的。
主题是分区的,这意味着一个主题分布在位于不同 Kafka 代理上的多个“桶”中。这种数据的分布式放置对于可扩展性非常重要,因为它允许客户端应用程序同时从多个代理读取数据或向多个代理写入数据。当新事件发布到主题时,它实际上会附加到主题的分区之一。具有相同事件键(例如,客户或车辆 ID)的事件被写入同一分区,并且 Kafka保证给定主题分区的任何消费者将始终按照与写入的顺序完全相同的顺序读取该分区的事件。
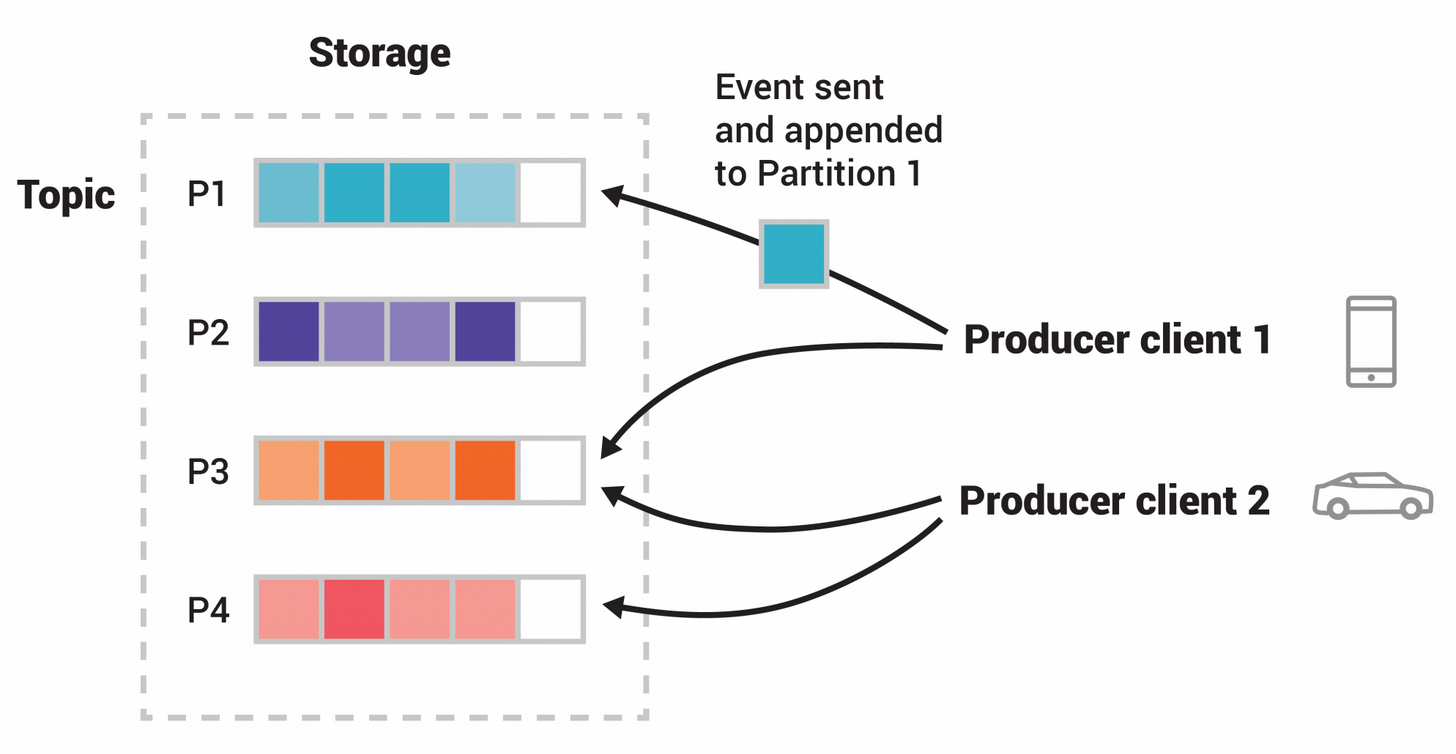
为了使您的数据具有容错性和高可用性,每个主题都可以复制,甚至可以跨地理区域或数据中心进行复制,因此始终有多个代理拥有数据副本,以防出现问题时,您希望对经纪人进行维护等等。常见的生产设置是复制因子为 3,即始终存在数据的三个副本。此复制是在主题分区级别执行的。
这本入门读物对于介绍来说应该足够了。如果您有兴趣,文档的设计部分详细解释了 Kafka 的各种概念。
Kafka API
除了用于管理和管理任务的命令行工具之外,Kafka 还有五个适用于 Java 和 Scala 的核心 API:
- 用于管理和检查主题、代理和其他 Kafka 对象的 管理 API 。
- Producer API,用于将事件流发布(写入)到一个或多个 Kafka 主题。
- Consumer API用于订阅(读取)一个或多个主题并处理为其生成的事件流。
- Kafka Streams API用于实现流处理应用程序和微服务。它提供了更高级别的函数来处理事件流,包括转换、有状态操作(例如聚合和连接)、窗口、基于事件时间的处理等等。从一个或多个主题读取输入,以便生成一个或多个主题的输出,从而有效地将输入流转换为输出流。
- Kafka Connect API用于构建和运行可重用的数据导入/导出连接器,这些连接器消耗(读取)或生成(写入)来自外部系统和应用程序的事件流,以便它们可以与 Kafka 集成。例如,关系数据库(如 PostgreSQL)的连接器可能会捕获对一组表的每个更改。然而,在实践中,您通常不需要实现自己的连接器,因为 Kafka 社区已经提供了数百个现成的连接器。
从这往哪儿走
- 要获得 Kafka 的实践经验,请按照快速入门进行操作。
- 要更详细地了解 Kafka,请阅读文档。您还可以选择Kafka书籍和学术论文。
- 浏览用例,了解我们全球社区中的其他用户如何从 Kafka 中获取价值。
- 加入当地的 Kafka 聚会小组, 观看Kafka 社区主要会议 Kafka Summit 的演讲。